
ROKO
[coursera] Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization: Week 1 본문
[coursera] Improving Deep Neural Networks: Hyperparameter tuning, Regularization and Optimization: Week 1
RO_KO 2024. 6. 30. 21:55Applied ML is a highly iterative process
최적의 hyperparameter를 찾기 위해서는 반복적인 과정이 필요할 수 밖에 없다.
Train/dev/test sets
예전부터 train:test=7:3 혹은 train:dev:test=6:2:2 로 설정하여 실험을 진행하였지만, 현재 빅데이터의 시대에 들어서면서 굳이 많은 양의 dev, test sets 이 필요하지 않게 되었다. dev, test의 목적은 모델이 잘 학습되었는지 확인하고자 하는 용도이기 때문에 적은 데이터로도 충분하다.
따라서100만개의 매우 많은 데이터가 있다고 가정한다면 train:dev:test=98:1:1 으로 분할하여 사용한다. 만약 100만개 이상이라면 train:dev:test=99.5:0.25:0.25 혹은 train:dev:test=99.5:0.4:0.1 로 사용할 수 있다.
데이터 분할에서 중요한 점 중 하나는 mismatched train/test distribition이다. 예를 들어 고양이 분류 사진이더라도 고해상도 이미지로 학습 데이터로 사용하고 저해상도 이미지를 평가 데이터로 사용할 경우 데이터의 특징 분포가 일치하지 않아 모델 학습에 어려움을 겪을수도 있다.
Train/dev? Train/test?
머신러닝에서는 train, dev ,test sets에서 test set을 제외하고 dev set을 test set 역할로서 사용하는 경우도 있다. 이때 dev set에 overfitting되는 문제는 cross validation과 같은 평가기법으로 최대한 완화하려고 노력하지만 overfitting을 막을수는 없다. 따라서 train / test sets 구조에서는 test set보다 dev set이라고 부르는게 더 적합하다. 왜냐하면 test set은 모델이 참고한적 없는 순수하게 독립적인 데이터로 성능을 평가하기 위해 구성되는데 train, dev, test 구조가 아닌 train dev(test) 구조에서는 간접적으로 dev(test) 데이터를 참고하여 과적합되기 쉽고 test set 목적보다 dev set 목적에 가깝게 이용되기 때문이다.
Bias/Variance

bias가 큰 경우에는 모델이 undeffitting 될 확률이 높고 vairance가 큰 경우에는 모델이 과적합 되기 쉽다. high bias와 high variance는 동시에 일어나기에 어려워 보이지만 예시와 같은 2D가 아닌 high dimension 데이터로 확장할 경우 흔히 일어날 수 있다.
이러한 문제점을 학습시에 어떻게 알 수 있을까? trian/test sets의 역할이 바로 그것이다.

train, dev, test sets에 데이터 분포가 균등하게 분할되었다고 가정하자. 이때 train과 test의 error graph를 보고 학습이 어떻게 되고있는지 파악하면 된다. 추가로 error가 무조건 0이어야 좋은것은 아니다. bayes error를 기준으로 bayes error에 근사할수록 generalization이 잘 반영된 학습 결과이다.
Basic recipe for ML
- Check high bias
- Solutions: bigger network, longer training, NN architecture search
- Check high variance
- Solutions: more data, regularization, NN architecture search
- Repeat until get low bias and low variance
Bias variance tradeoff
전통적인 기계학습에서는 둘 다 값을 낮춰 성능을 올리는 방법이 존재하지 않았다. 하지만 딥러닝 이후로 더 큰 모델과 그에 상응하는 더 많은 데이터를 모을 수 있게 되면서 한쪽에 영향을 덜 끼치며 두 관점 모두 향상시킬 수 있었다.
Regularization
가장 좋은 일반화 성능을 얻는 방법은 추가적인 데이터를 얻는 것이다. 하지만 아무리 데이터가 많다한들 여전히 유한하기 때문에 대안으로 규제 (regularization) 기법을 많이 사용한다. 현재 regularization term 에는 가중치 W를 사용하는데 왜 편향 b는 사용하지 않을까? 왜냐하면 W가 b보다 많은 변수들을 가지고 있고 더 큰 영향을 미치기 때문이다.
- L2 regularization: \(||W||_2=\sum^{n_x}_{j=1}w_j^2\)
- L1 regularization: \(||w||_1=\sum^{n_x}_{j=1}|w_j|\)
L2,L1 차이를 나타내기 위한 수식 표기는 forbenius norm(행렬의 크기를 표현)에 subscript 1,2로 되어 있다. L2는 과적합을 방지하기 쉽다. L1은 모델 가중치를 sparse하게 만들어 0이 많아 가벼운 모델을 만들기에 좋다.
\(w^{[l]}:=w^{[l]}-\alpha[(from \, backprop)+\frac{\lambda}{m}w^{[l]}]\)
L2는 \((1-\frac{\alpha \lambda}{m})\)만큼 가중치가 감소하여 반영되기 때문에 가중치 감쇠(wight decay)라고도 불린다.
규제 기법이 과적합을 막는 이유로는 여러 관점이 있는데 W 노드들중 여러 노드들에 영향을 크게 미치는 값들을 zeroing-out 하면서 모델은 단순하게 만들어 준다고 생각할 수 있다. 활성함수와 연관지어 생각한다면 tanh 그래프에서 W값들이 0에 가까워지면 행렬 연산 이후의 Z 값들도 0에 가깝게 되어 tanh을 거칠때 linear한 가운데 부분을 통하며 똑같이 모델이 단순해지도록 한다.
Dropout
이 기법은 L2 규제기법가 잘되는 이유를 바탕으로 theoritical 보다 practical한 관점에서 적용한 기법이다. 학습때 dropout 확률을 지정하여 일부 노드들을 zeroing out 하는데 추론시 분포를 보정하기 위해 확률값을 결과값에 곱해주거나 학습과정에서 출력에 확률값을 나누어준다(inverted dropout). dropout이 잘 작동하는 이유는 학습과정에 랜덤으로 노드들을 0으로 만들기 때문에 각 노드들이 특정 특징에 의존하여 학습하는걸 방지해 일반화를 높이기 때문이다.
dropout을 사용하게 되면 다른 코드에 문제가 있는지 아닌지를 파악하기 어렵다. 초반에 그래프가 단조감소하지 않을 수 있기 때문인데 dropout을 사용할 예정이라면 dropout을 제외한 코드가 잘 동작하고 loss 가 단조감소하는지 확인 후 적용하느걸 추천한다. 컴퓨터 비전에서는 데이터의 특성으로 인해 기본으로 사용하지만 대부분의 상황에서 drop out을 쓰는걸 추천하지는 않는다.
Other regularization methods
Data augmentation (데이터 증강): 이미지 데이터의 경우 왜곡, 자르기, 확대 등등 다양한 방식을 통해 데이터를 늘려 일반화를 높일 수 있다.
Early stopping: optimize cost function과 prevent overfitting은 orthogonalization 관계인데 이를 둘다 해결할 수 있다. 또한 L2와 같은 기법은 \(\lambda\) hyperparameter를 찾아야하는데 early stopping은 그럴 필요가 없다.
Normalization
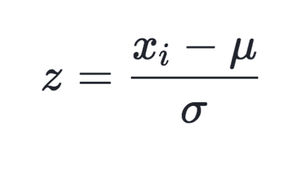
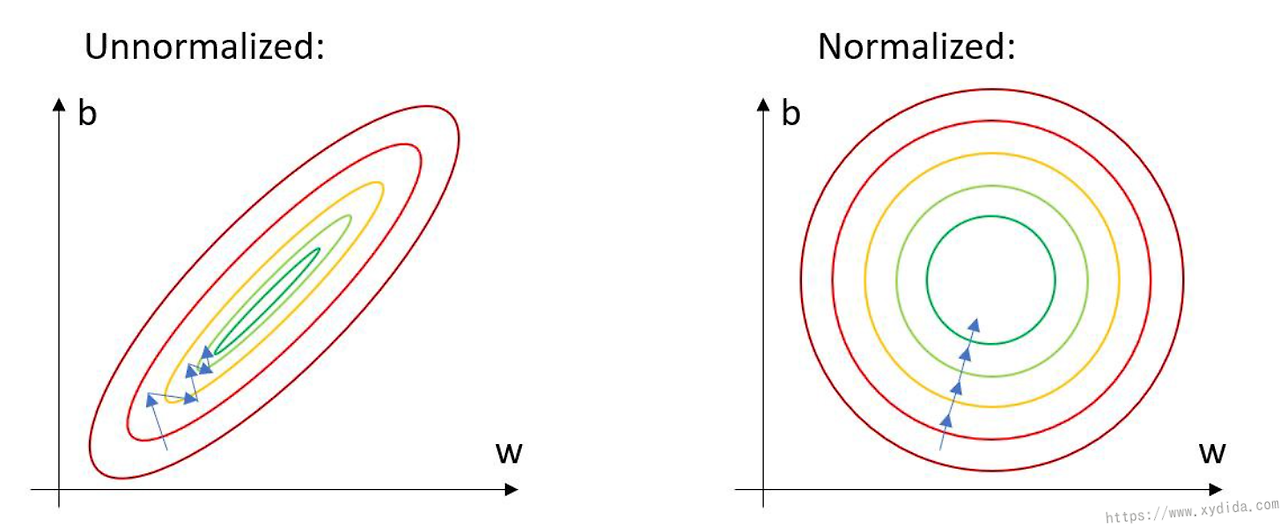
데이터를 정규화 하는것은 학습에 많은 도움이 된다. 정규화가 되지 않은 경우, 분산이 큰 축에서 최적화하는 과정에서 많은 step이 필요하게 된다.
모델이 데이터를 정규화하여 학습할 경우 추론시에도 같은 정규화 방시을 따라야한다. 그러므로 test set의 평균 분산을 따로 구한는 것이 아니라 train set에서 구한 평균 분산을 그대로 사용해야한다.
Vanishing/exploding gradient
가중치의 값들이 1보다 크거나 작으면 층이 많은 신경망에서 값이 지수적으로 증가하거나 감소하여 역전파시 그래디언트가 exploding하거나 vanishing될 수 있다.
부분적인 해결방안
- Xavier initialization ~ tanh
- He initialization ~ ReLU
gradient checking: backprop이 정상적으로 동작하는지 확인하는 단계이다. numeric 방식으로 \(\frac{f(\theta+\epsilon)-f(\theta-\epsilon)}{2\epsilon}\)을 사용한다.
\( d \theta_{approx}[i] = \frac{J\theta_1,\cdots,\theta_i+\epsilon,\cdots)-J(\theta_1,\cdots,\theta_i-\epsilon,\cdots)}{2\epsilon}\)
Check \(\frac{||d\theta_{approx}-d\theta||_2}{||d\theta_{approx}||_2+||d\theta||_2}\)
- \(10^{-1}\) 정상
- \(10^{-5}\) 한번 확인 필요
- \(10^{-3}\) 코드에 우려가 있을 확률 높음



