
목록분류 전체보기 (117)
ROKO
Python은 OOP이다. 객체를 이용해 프로그래밍을 한다는 뜻인데, 객체가 너무 많아지게 되면 RAM에 부하가 늘어나면서 전체적인 프로그램의 성능이 낮아지게 될 것이다. 이미 사용된 객체는 어떻게 관리해야할까? 기본적으로 python은 사용자가 직접적으로 동적할당과 해제를 할 필요가 없는 언어이다. 모든 type이 이미 객체화가 되어 있기 때문이다. 그렇다면 heap영역을 쓰지 않는 걸까? 그렇지 않다. 내부적으로 python memory manager가 존재하여 해당 객체가 사용될때 heap에 할당하여 자동적으로 메모리 관리를 해준다. 미리 할당하지 않고 사용시에 할당하는 방식은 OS heap 영역의 과부하를 막아주게 된다. 사용된 변수들은 reference counting 방법을 통해 GC(garb..
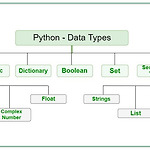 [Python] OOP (Object Oriented Programming)
[Python] OOP (Object Oriented Programming)
Python은 OOP를 강제하지는 않지만 방향성을 제공하는 언어이다. 객체 지향 프로그래밍이란 절차지향과 같이 순차적으로 logic을 구성하는것이 아닌 객체들간의 관계로 logic을 구성하는 것을 의미한다. 객체는 class로 부터 생성된 변수로 속성과 함수를 가지고 있는 변수이다. 파이써의 모든 구성 요소는 객체로 정의되어 사용된다. 용어 정리 객체(object) : 파이썬에서 추상화되어 표현되는 데이터 변수(variable) : 객체를 관리하기 위한 메모리 영역 (Ex x = 10, x 는 10이라는 literal을 의미하는 변수) 식별자(identifier) : entity를 구별하기 위해 사용되는 이름 (식별자가 같은 경우 변수에 값이 재할당) id,dientity : 객체 정보가 저장된 변수의 ..
Python의 특징 중 하나로 bulit-in function이 있다. 별도의 import문이 없어도 실행 가능한 내장함수들을 의미한다. C,C++만 하더라도 stdlib, iostream 등 필수 표준라이브러리가 있다고 하더라도 include를 통한 (python기준으로는 import)는 필수 불가결하다. 하지만 파이썬은 가능하다. [예시] print("hello") # hello 출력 printf("hello") # error! printf는 bulit-in 이 아님! Python bulit-in function https://docs.python.org/3/library/functions.html Built-in Functions The Python interpreter has a number of..
ML,DL을 tensorflow, pytorch로 하다보니 python을 이용해 코드를 주로 짜게 되었다. 이 과정에서 python 언어 자체에 대한 이해도가 필요하다고 느껴 파이썬을 프로그래밍 언어로써 공부하고 파이썬을 이용해 다양한 알고리즘 문제를 풀며 구현 능력을 향상 시키려고 한다. [참고자료] https://www.python.org Welcome to Python.org The official home of the Python Programming Language www.python.org https://docs.python.org/ko/3/tutorial/index.html The Python Tutorial Python is an easy to learn, powerful programmi..
 [취업준비] 취업 스펙, 후기 보는법
[취업준비] 취업 스펙, 후기 보는법
3,4학년이 되면 취업에 대해 고민을 하고 학교에서 전공 수업만 들은게 전부인 본인은 궁금하게 된다. 공부만 해서 취업 할 수 있나? 취업하려면 도대체 어떤 스펙이 필요한거지? 잡코리아, 사람인 등등 다양한 취업 포털 사이트에서 취업수기를 써놓는 경우가 있다. 하지만 정보를 확인하기 위해서는 금액을 요구하는 경우가 많기에 "무료"로 정보를 얻는 방법에 대해 간략히 알아보자. 전북대학교 취업지원과 학교를 다니며 취업지원과는 별로 도움이 안된다고 생각하거나 참여한 경험도 거의 없는 경우가 많다. 이와 다르게 잘 찾아보면 학교와 제휴를 맺은 취업 포털 사이트나 연계프로그램이 많이 있으니 매일매일 찾아보며 관련 직무가 올라오면 꼭 챙기도록 하자. https://career.jbnu.ac.kr/career/ind..
Python에서 list를 정렬하는 방식은 LIST.sort() 와 sorted(LIST) 2가지 방식이 있다. 두개의 차이점은 무엇이고 어떤것이 더 효율적일까? LIST.sort() 우선 LIST.sort()는 리스트 메서드로 inplace형식이다. 실행한 list자체가 값이 수정되므로 return 값이 None이다. list1 = [4, 3, 2, 1] list2 = list1.sort() print(list1) # [1, 2, 3, 4] print(list2) # None sorted(LIST) sorted는 python 표준 내장 함수로 inplace형식이 아니라 정렬된 새로운 객체를 반환한다. list1 = [4, 3, 2, 1] list2 = sorted(list1) print(list1) #..
baekjun이나 google의 코딩테스트 사이트인 hackearth에서 나는 주로 python을 이용했다. 물론 코딩테스트 관점에서 좋은 언어 선택은 아니다. (모든 언어를 다룰 수 있다는 전제하에) Why? python은 생산성과 다양한 기능을 하는대신 최적화에는 알맞지 않다. C++, C가 최고 python은 다양한 역할군에 쓰이지 않는 언어이다. 물론 요기요도 일부 python구현이 있다고는 하나 한국은 java기반의 언어가 대부분이다. python은 대체로 AI 분야에서 사용되는 언어이다. (본인은 AI의 길을 걷고자 하기에...) 따라서 복잡하고 세밀한 설계가 필요한 알고리즘 문제일 경우 input()을 사용함에 따라 시간 초과가 생길수도 있는데, 이를 해결하기 위해 import sys inp..
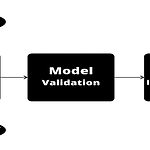 Is validation necessary?
Is validation necessary?
딥러닝 논문들을 보면서 experiment에 validation없이 train-test로 실험한 결과들이 다수 있었다. 이러한 방식은 overfitting에 문제가 없을까? validation을 추가해 실험하는 기법중 cross-validation은 overfitting을 막고 모델의 성능을 검증하기 위한 좋은 방법이다. cross-validation은 2가지의 목적을 가지고 있는데, validation의 선택에 따라 train-test의 데이터 분포가 편향되어 성능이 다르게 나올 수 있다. k-fold를 통해 총 성능의 평균을 기준으로 하므로 더 general한 모델을 찾기 좋다. ML의 logistic regression의 parameter인 C값과 같은 hyperparameter를 결정하는데 도움이..
딥러닝은 모델의 parameter 자체가 많아 많은 데이터가 필요하다는 것을 알고 있다. 관련 생각을 하던중 궁금증이 생겼다. 어떠한 기준을 바탕으로 어느정도의 데이터가 필요할까? 딥러닝과 머신러닝을 학습시키기 위한 양은 비슷할까? 1번 질문 일반적으로 두가지의 대답을 할 수 있는데, "어떠한 프로젝트를 진행중이냐는 의존성"과 "많으면 많을수록 좋다"라는 것이다. 의존성에 대해 먼저 살펴보자 모델을 학습함에 있어 고려해야할 사항은 어떤 것들이 있을까. 문제의 복잡성 (정형, 비정형, 단변량, 다변량) 모델의 복잡성 (머신러닝, 딥러닝) 목표 성능 (허용 에러 수치) 문제의 복잡성이란 데이터의 단순함 정도를 의미할 수 있다. 대표적인 머신러닝 데이터셋인 iris를 예를 든다면 꽃에 대한 길이정보를 가지고 ..
Numpy docs [link] 어떠한 값을 확인하려 print()문을 많이 사용하는데, shape크기가 클 경우 "..." 형태로 생략이 되는 경우가 많다. 억지로라도 전체 출력을 통해 값을 확인하고 싶은 경우 어떻게 해야 할까? numpy.set_printoptions() numpy.set_printoptions(precision=None, threshold=None, edgeitems=None, linewidth=None, suppress=None, nanstr=None, infstr=None, formatter=None, sign=None, floatmode=None, *, legacy=None) 위 명령어를 사용하면 된다. 설정을 수정하는 명령어인데, parameter를 통해 어디까지 출력하게 ..