
ROKO
Probabilistic models [Ⅱ] 본문
이전 포스트에서는 MLE 방식을 통해 롹률모델을 최적화하는 방법을 알아보았다.
Maximum likelihood(MLE)의 단점
- Data sparsity -> overfitting
- 최대 가능도에 대한 확률을 데이터셋의 분포를 통해 결정하므로 데이터가 적은 경우나 편향 된 경우 잘못 추정할 수 있다.
Bayesian parameter estimation
- MLE에서 dataset을 random variable로 보지만, parameter는 그렇지 않다.
- Bayesian approach는 parameters 또한 prioir로부터 얻어진 random variable로 본다.
- Bayesian model을 정의하기 위해서는 prior distribution과 likelihood 가 필요하다.
Posterior distribution with Bayes rule's : \(p(\theta | D) = \frac{p(\theta)p(D|\theta)}{\int p(\theta')p(D|\theta')d\theta'}\)
denominator(분모식)는 거의 계산하지 않는다.
Why?
계산하기도 어렵고, \(p(D)\)라는 고정된 상수값이 나오게 되는데 우리가 최대화 하고자 하는 값과 관련이 없으므로 고려하지 않아도 된다.
예를들면 x든 2x든 최대화 상수값은 상관없이 x의 값을 고려하면 되는것과 같다.
동전던지기 예시를 이번엔 likelihood를 최대화하는 MLE가 아니라 posterior를 최대화하는 MAP 방식으로 진행해보자.
likelihood는 MLE와 동일한 방식으로 구현하면 되는데 prior를 결정하는 것이다. 물론 무정보적(uninformative) 사전분포로 영향이 거의 없게끔 정의할 수는 있지만 합리적인 선택은 uniform prior이다. uniform prior를 선택하면 MLE와 다를 바 없기는 하다.
그럼 MAP는 MLE보다 어떤 점이 장점이기에 베이지안 기법이 뜨는 걸까?
- 앞에서 MLE의 data sparsity문제를 언급했는데 이를 어느정도 완화시켜 준다.
- conjugate function 관계를 이용해 계산의 효율성을 높일 수 있다. (장점보다는 트릭?)
동전 던지기 예시에서 우리가 관측을 2번까지만 했을때 모두 앞면이 나왔다면 MLE는 관측데이터를 기반으로 최적해를 얻어내기에 앞면이 1의 확률로 나올때 2번의 관측이 모두 앞면이 확률이 된다. 만약 우리가 해당 사건의 확률만 필요하다면 맞는말이지만 정확히 얻고자 하는건 일반화된 상황에서 확률이다. 일반화된 상황에선 overfitting이 된 상황인데 우리가 사전 분포를 보통 앞면 2번 뒷면 2번으로 나온다고 가정한다면 관측데이터까지 포함해서 앞면 4 뒷면 2이므로 2/3이 된다.
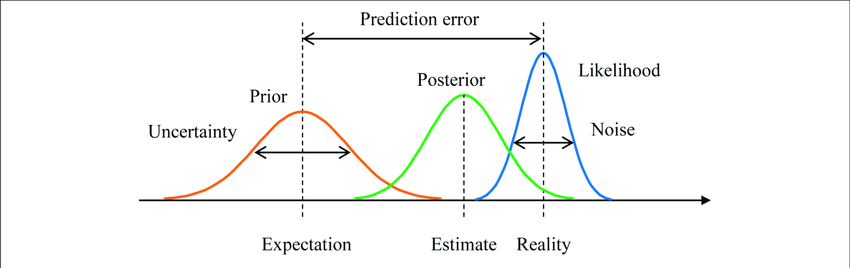
데이터가 많아지면 많아질수록 사전분포보다 관측데이터를 기반으로 확률이 영향을 받으므로 사전분포가 끼치는 영향을 데이터가 많을때까지는 고려하지는 않아도 된다. 사전분포의 큰 역할은 데이타가 충분하지 않을때 과적합되지 않도록 조정해주는 역할이다.
Posterior predictive distribution
\(p(\theta|D) \propto p(\theta)p(D|\theta)\)
marginalizing out the parameters:
\(p(D'|D)=\int p(\theta|D)p(D'|\theta)d\theta\) D : future observation, D' : past observation
Differnce with MLE vs Bayesian parameter estimation
- MLE(Maximum Likelihood Estimation) : optimization problem
- FB(Full Bayesian) : integral problem, expectation
- There is no black-box tools for FB
ex) coin flip by Bayesian Parameter Estimation
\(\theta_{pred}=Pr(x'=H|D)\)
\(=\int p(\theta|D)Pr(x'=H|\theta)d\theta\)
\(=Beta(\theta;N_H+a,N_T+b)\cdot d\theta\)
\(=E_{Beta(\theta;N_H+a,N_T+b)}[\theta]\) why? \(\int p(x)xdx = E[x]\)
\(=\frac{N_H+a}{N_H+N_T+a+b}\)
MAP(Maximum A-Posteriori Estimation)
Convert the Bayesian parameter estiamtion problem into a maximization problem
\(\hat{\theta_{MAP}}=\underset{\theta}{argmax} p(\theta|D)\)
\(=\underset{\theta}{argmax} p(\theta,D)\) why? \(p(D)\) is just constant not related with maximization
\(=\underset{\theta}{argmax} p(\theta)p(D|\theta)\)
\(=\underset{\theta}{argmax} logp(\theta)+logp(D|\theta)\) why? log is increasing function s.t conserve sequence relation
FB방식을 수식변환을 통해 MAP문제로 변환하면 integral문제를 고려하지 않고 좀더 쉽게 추정할 수 있다.
ex) coin flip by MAP
\(logp(\theta,D) \propto logp(\theta)+logp(D|\theta)\)
\(=Const+(a-1)log\theta +(b-1)log(1-\theta)+N_Hlog\theta+N_Tlog(1-\theta)\)
\(=Const+(N_H+a-1)log\theta + (N_T+b-1)log(1-\theta)\)
Maximizing by differentiate
\(0=\frac{d}{d\theta}logp(\theta,D)=\frac{N_H+a-1}{\theta}-\frac{N_T+b-1}{1-\theta}\)
\(\hat{\theta}_{MAP}=\frac{N_H+a-1}{N_H+N_T+a+b-2}\)
| \(a=b=2\) | Formula | \(N_H=2,N_T=0\)(prior) | \(N_H=55,N_T=45\)(obs) |
| \(\hat{\theta}_{ML}\) | \(\frac{N_H}{N_H+N_T}\) | 1 | 55/100=0.55 |
| \(\theta_{pred}\) | \(\frac{N_H+a}{N_H+N_T+a+b}\) | 4/6~0.67 | 57/104~0.548 |
| \(\hat{\theta}_{MAP}\) | \(\frac{N_H+a-1}{N_H+N_T+a+b-2}\) | 3/4=0.75 | 56/102~0.549 |
MAP로 추정할 경우 a,b값이 1보다 커야 nonzero probability가 나오는 것을 알 수 있다.
3가지 방식 모두 데이터가 적은 초반에는 다른 확률을 보이지만 관측데이터가 충분히 많아질수록 같은 확률로 수렴한다.
'Machine Learning' 카테고리의 다른 글
| K-Means (0) | 2023.03.16 |
|---|---|
| Generative models (0) | 2023.03.15 |
| Probabilistic Models [Ⅰ] (4) | 2023.03.12 |
| MLOps (0) | 2023.03.10 |


