
ROKO
[coursera] Convolutional Neural Networks: Week 2 본문
LeNet -5

활성함수로 ReLU가 아닌 sigmoid/tanh를 썼다. 논문 section 2,3 에 흥미로운 내용을 담고 있으니 읽어보기 추천한다.
http://vision.stanford.edu/cs598_spring07/papers/Lecun98.pdf
AlexNet
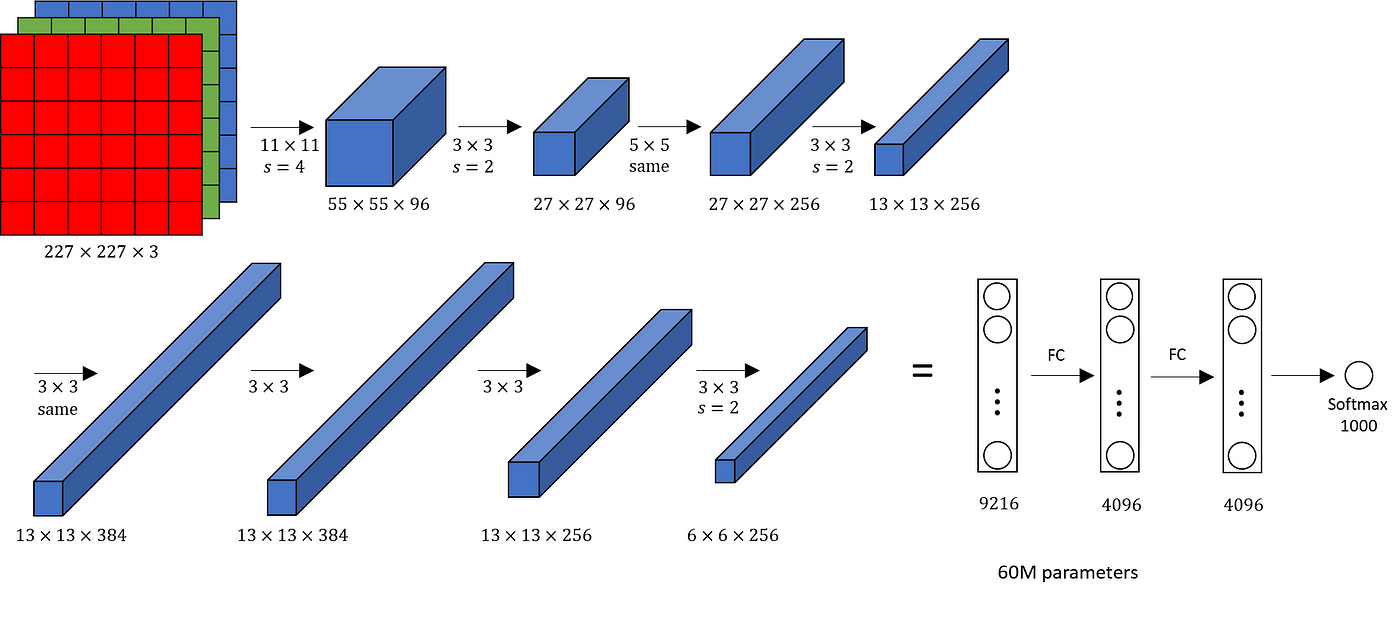
당시 자원의 한계로 multi-gpu를 사용해 학습하였다. Local Response Normalization (LRN)을 사용했는데, channel 을 기준으로 정규화하는 방법이다. 현재는 사용하지 않는다.
VGG-16

적은 parameter를 사용하지만 연산량이 그만큼 늘어난다. 계층적 filter를 통해 recepive field가 filter가 큰 경우를 해결한 논문이다.
ResNets

ResNet의 motivation은 신경망이 깊을수록 이론상 더 잘 학습하여야 하는데 실제 결과는 error가 다시 증가하는 모습을 보여준다.

이를 해결하고자 LeRU 활성함수 이전에 skip connection을 통해 gradient vanshing/exploding 문제를 완화한다. skip connection을 통해 깊은 층의 가중치가 0이 되더라도 identiy function을 통해 성능을 유지한다. residule connection 을 하기위한 activation 차원이 서로 다르다면 extra matrix를 곱해주어 차원을 맞춰주면 된다.ResNet은 차원을 맞춰주기 위해 3x3 filter를 사용한다.
1x1 convolution

element-wise 곱으로 channel끼리 곱하여 feature size의 volume을 줄여준다. 주로 network in network 구조에서 사용된다.


원하는 모든 filter size를 적용해 다양한 feature를 볼 수 있지만 computational cost가 너무 커지게 되어 bottleneck이 생긴다. 해결책으로 inception module에서는 1x1 convolution을 통해 overhead를 낮춘다.

inception module은 GoogleNet의 일부로 사용된다.
MobileNet
딥러닝 모델을 edge device에 돌리기에는 이전 모델들은 너무 큰 하드웨어를 요구한다. MobileNet은 이 문제를 normal convolution을 depthwise-seperable convolution으로 대체해 해결한다.
Step 1. depthwise convolution
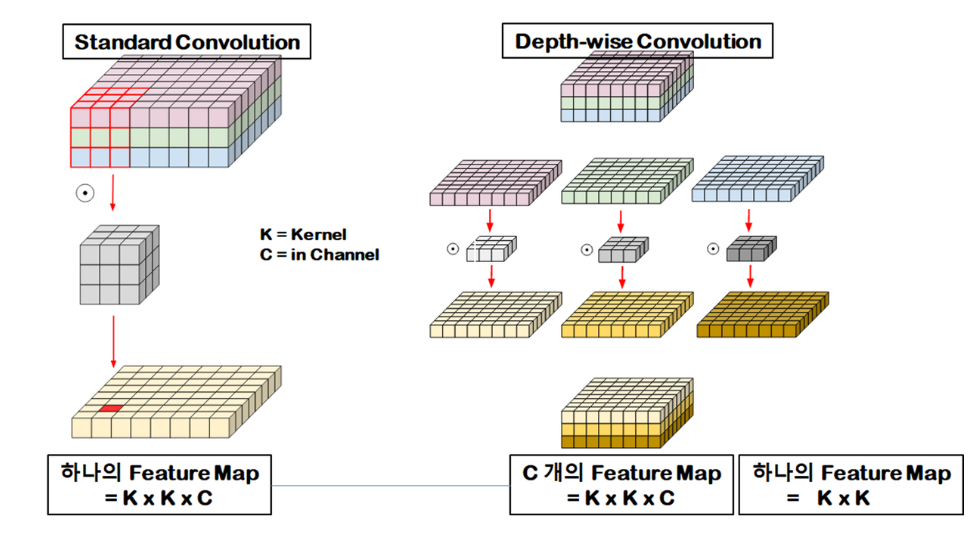
Step2. pointwise convolution

MobileNet v1 vs MobileNet v2

EifficientNet

한정된 자원에서 여러 모델의 scailing을 가장 효과적으로 정하는 공식을 실험적으로 증명한 논문이다.
Practical advice for using ConvNets
데이터가 적은 경우
- ensemble
- multi-crops at test time
- use open source code (recommend)
'Deep Learning' 카테고리의 다른 글
| [coursera] Convolutional Neural Networks: Week 3-2 (0) | 2024.07.03 |
|---|---|
| [coursera] Convolutional Neural Networks: Week 3-1 (0) | 2024.07.03 |
| [coursera] Convolutional Neural Networks: Week 1 (1) | 2024.07.02 |
| [coursera] Introduction to ML Strategy: Week 2 (0) | 2024.07.02 |



