
ROKO
[CS234] Reinforcement Learning: Lecture 4 본문

1번 질문은 Deterministic이다. policy 식을 보면 arg max로 가장 큰 값을 가지는 선택지 하나를 선택하는 것이므로 deterministic하다. 2번 질문은 False이다. policy가 deterministic 이므로 모든 s,a에 대해서 값을 구할 수는 없다. 가장 좋은 값을 가지는 선택지 하나만 선택하여 임의의 action에 대해 exploration을 하지 않기 때문이다.
3 장에서는 a model of how the world works 에서 evaluation을 보았다면 이번 장은 control에 대해서 알아본다.
2번 질문을 동기로 exploration을 하기 위한 방법론을 알아보자.
General Policy Iteration (GPI)


Policy Iteration과 Policy Evaluation이 서로 상호작용하는 개념 자체를 GPI 라고 부른다.대부분의 강화학습은 GPI로 설명 가능하다.
\(\epsilon\)-greedy Policies

\(\epsilon\)-greedy policy는 policy improvement theorem을 만족한다. \(\epsilon\)만큼 다른 action에 확률을 분배해주어 deterministic이 아닌 stocastic으로 action을 선택한다. 이는 exploration을 가능하게해 더 좋은 action을 학습할 수 있는 기회를 얻게 된다.

Monte Carlo Online Control / On Policy Improvement

Monte Carlo 에 Q value 값을 목적으로 학습하는 코드이다. On-policy improvement는 8번 12번 line을 보면 target value와 behavior action 모두 같은 policy를 사용하기 때문이다. 둘이 다른 경우는 off-policy라고 부른다. 또한 12번째 line에는 exploration을 위해서 \(\epsilon\)-greedy 를 적용하였다.
Greedy in the Limit of Infinite Exploration (GLIE)

A simple GLIE strategy is \(\epsilon\)-greedy where \(\epsilon\) is reduced to 0 with the following rate: \(\epsilon_i = 1/i\)

Temporal Difference Methods for Control

대표적인 on-policy TD method인 SARSA 의 수식이다. SARSA는 state-action-reward-state-action에 대해 update하는 방식으로 앞글자만 따서 만든 표현이다. 8번 줄을 보면 \(\epsilon\)-greedy 또한 적용하였다.
Convergence properties of SARSA

Properties of SARSA with \(\mathbf{\epsilon}\)-greedy policies
- Result builds on stochastic approximation
- Relies on step size decreasing at the right rate
- Relies on Bellman backup contraction property
- Relies on bounded and value function
Om and Off-Policy Learning
위에서 한번 언급했던 on-policy 와 off-policy 의 차이를 알아보자

On-policy의 예시로 SARSA가 있고 off-policy의 예시로는 Q-learning이 있다.
Q-Learning: Learning the Optimal State-Action Value

Q-learning이 받는 reward는 arg max를 취한 결과를 받지만 학습과정에서 하는 행동은 exploration을 위해 \(\epsilon\)-greedy 를 사용한다. 즉 behavior policy 와 value policy가 일치하지 않는다. 따라서 off-policy이다.

Optional Check Understanding SARSA and Q-Learning Solutions

1번과 2번 모두 정답이다. 1번은 알고리즘 정의를 살펴보면 쉽게 알 수 있다. 2번은 \(\epsilon=0\)이면 어떤 action이든 max가 되도록 하는 action을 취하게 되므로 Q-Learning은 on-policy 가 되고 SARSA와 같은 Q값을 update하게 된다.
Model Free Value Function Approximation
1강부터 살펴본 내용은 model-based, model-free 를 table data에 적용하는 방법론들이였다. state나 action space가 더이상 finite하지 않고 countable하거나 uncountable하다면 메모리가 너무 커져 너무 많은 시간이 소요되거나 학습 자체가 안될 것이다. 세상은 continuous space인 경우가 많으므로 일반화하기 위해서 고려해야 할 사항들이 있다.


State Action Value Function Approximation for Policy Evaluation with an Oracle
임의의 state s, action a에 대해 state action value를 얻을 수 있다고 가정하자. 지도학습과 같이 \(((s,a),Q^{\pi}(s,a))\) 데이터가 존재한다면 학습데이터로 사용하여 \(Q^{\pi}\)를 추정하는 \(\hat{Q}(s,a;w)\)를 학습할 수 있다.


Model Free Value Function Approximation / Policy Evaluation

Monte Carlo Value Function Approximation


Temporal Difference TD(0) Policy Evaluation

evaluation 을 state value로 하는것에는 이유가 있는건 아니니 고민하지 않아도 된다. (state value, state action value 둘다 가능)


Control using Value Function Approximation

Function approximation, bootstrapping, off-policy learning을 사용했을때 모델 학습에 불안정성을 가져올 수 있다. 이 세 방식을 "Deadly triad"라고 부른다.

Value function approximation 방식은 다양한 방법론에 적용가능하다. MC인 경우 True value를 return 으로 TD를 사용할 경우 bellman equation을 사용한다.
Deep Q-Learning


Atari 게임을 강화학습으로 해결하고자 한 논문에서 제안된 알고리즘이다.

DQN의 한계점에 자세히 살펴보자.
- Correlations between samples이란 정확히 말하면 temporal correlation을 의미한다. 시간의 흐름에 따라 순차적으로 수집된 학습데이터는 근접한 sample끼리 높은 correlation을 가진다. episode는 분리되어 있지만 temporal하게 연결되어 있는 학습데이터라면 모델이 해당 temporal data에 편향되어 불안정한 학습이 된다.
- Non-stationary targets 이란 DQN은 off-policy에 VFA를 사용하는데 target value가 update마다 수정되면서 고정된 target value가 아닌 변화하는 target value를 추정해야하기 때문에 학습에 어렵다는 의미이다.


DQN Pesudocode


DQN을 target network를 하나 더 만들어 delayed update를 진행하는것이므로 computation이 아닌 memory가 2배가 된다.

DQN은 이미지를 input으로 받아 Q(s,a)를 output으로 내보낸다. 출력된 Q값에서 가장 큰값을 가지는 action을 선택하면 된다.
Reason for not using DNN
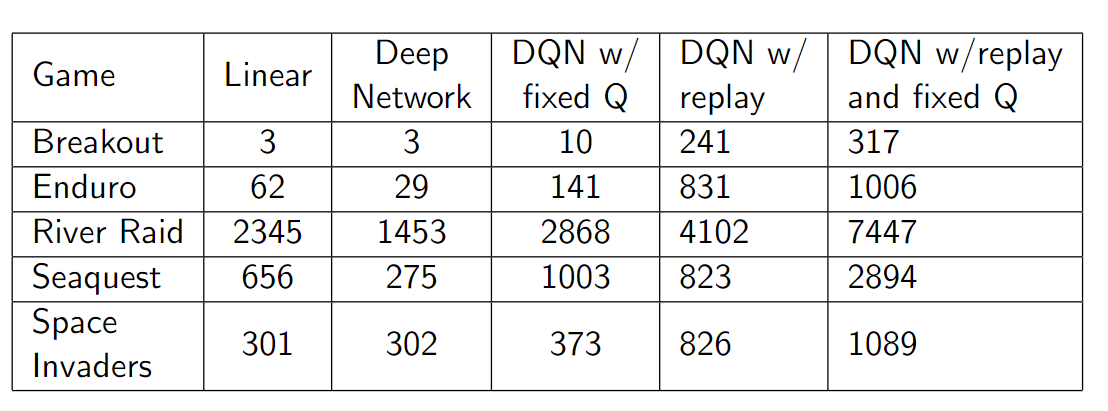
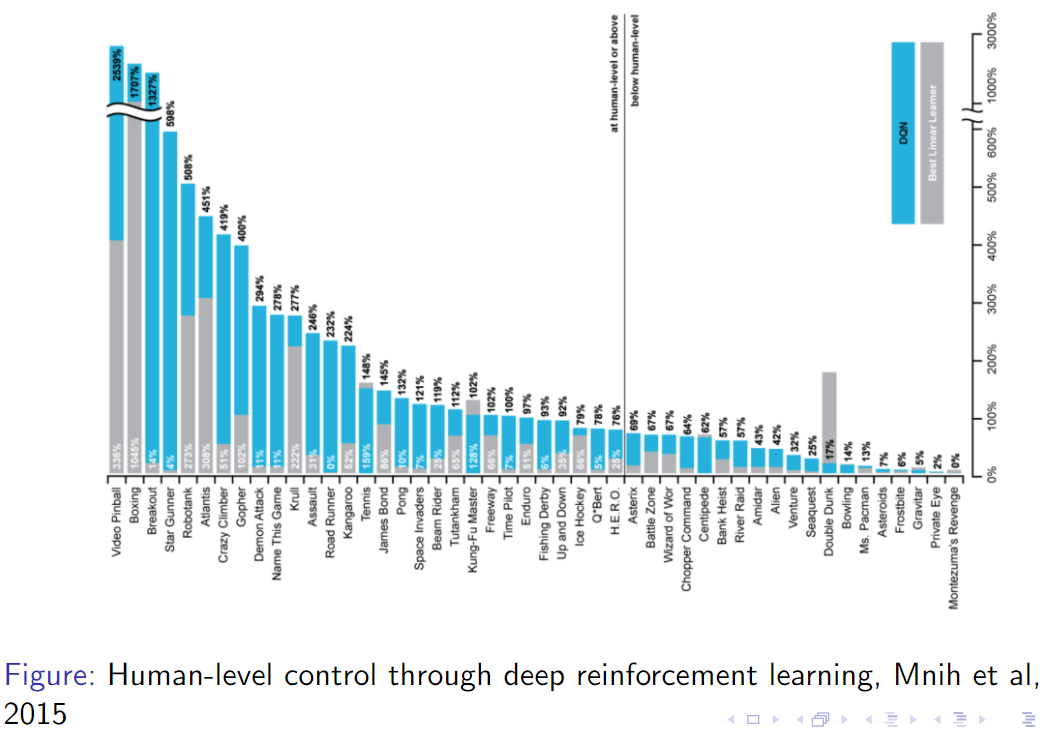
DNN보다 단순 Linear모델이 성능이 높은것을 보아 DNN만으로 해결할 수 없는 문제라는걸 보여준다. DQN이 Linear, DNN보다 좋은 성능을 보여주고 특히 experience replay(buffer)를 사용한게 큰 성능 향상을 일으켰다.
https://curt-park.github.io/2018-05-17/dqn/
[분석] DQN
Human-level control through deep reinforcement learning
curt-park.github.io
Follow work

'Deep Learning' 카테고리의 다른 글
| HuggingFace datasets은 dict 형태가 아니다 [?] (0) | 2024.11.23 |
|---|---|
| [CS234] Reinforcement Learning: Lecture 5 (0) | 2024.07.29 |
| [CS234] Reinforcement Learning: Lecture 3 (0) | 2024.07.16 |
| [CS234] Reinforcement Learning: Lecture 2 (0) | 2024.07.11 |


