
ROKO
[CS234] Reinforcement Learning: Lecture 2 본문
Markov Decision Process (MDP)
Markov Reward Process + actions
MDP is a tuple: \((S, A, P, R, \gamma)\)
- S: a set of Markov states \(s \in S\)
- A: a set of actions \(a \in A\)
- P: dynamics / transition model for each action \(P(s_{t+1}=s'|s_t=s,a_t=a)\)
- R: reward model \(R(s_t=s, a_t=a)=E[r_t|s_t=s, a_t=a]\)
- \(\gamma\): discount factor \(\gamma \in [0,1]\)
Policy: \(\pi(a|s)=P(a_t=a|s_t=s)\)

\((I-\gamma P)\) 에서 \(\gamma\)와 P 둘다 1인 경우를 제외하고 invertible하다.
위처럼 해석적으로 답을 바로 풀 수 있지만 \(O(N^3)\)의 computational cost가 들기 때문에 적용하기 어렵다.
따라서 Dynamic programming을 이용해 문제를 해결한다.

Bellman backup


특정 state에서의 value는 bellman backup을 통해 오른쪽 식으로 전개 될 수 있다.
https://jrc-park.tistory.com/279
[Remark] Why contraction property is important for Bellman operator
[Remark] Why contraction property is important for Bellman operator Bellman Equation은 value function이 만족하는 방정식으로 주어진 policy에 대해서 $V_\pi(s)$값에 대한 관계를 나타냅니다. 주어진 policy $\pi$에 대해서 Bell
jrc-park.tistory.com
MDP control
- Optimal policy는 \(\pi*(s)=arg \underset{\pi}{max}V^{\pi}(s)\) 식으로로 구한다.
- 이때 optimal value function은 유일하다. 그렇다면 optimal policy도 유일할까? 아니다! 모든 state의 value가 동일하다면 어떻게 움직이든 상관없으므로 다양한 policy가 나올 수 있다.
- infinite horizon에서 MDP를 구하면 deterministic 한 optimal policy가 나오고 stationary한 특징을 가지고 있다.
- deterministic policy의 개수는 \(|A|^{|S|}\)이다. 모든 policy를 계산하고 비교하는건 exponential하므로 policy iteration을 이용해 근사한다.
MDP Policy iteration (PI)

State-Action Value Q

state에 한정해 value를 계산하던 state value와 달리 state-action value는 해당 state에 어떠한 action을 취했을때의 value를 계산한다.

Q value 를 policy update에 적용하는 식이다. 수식의 유도과정은 아래와 같다.

정확히 말하면 수식의 유도과정이라기 보다 state value를 이용한 것보다 좋은 이유를 policy improvement theorem을 이용해 유도하는 과정이다.
Policy improvement theorem

정말 중요한 정리로 policy가 update될때마다 같거나 더 좋은 policy를 얻게되는 이유를 증명하는 것이다.
1. Policy update 과정중 한번 변하지 않았다면 그 이후로도 변하지 않을까? 그렇다 policy improvement theorem에 의해 변하지 않았다면 policy는 optimal policy 수렴한 상태가 된 것이다.
2. Policy iteration의 최대 횟수가 정해져있을까? 아니다 앞에 언급했듯이 deterministic policy의 개수는 action과 state개수의 지수승으로 표현가능하기에 정해져있다. 하지만 action과 state space가 continuous하면 infinte하므로 정해져 있지 않다.
Value Iteration (VI)

Contraction Operator
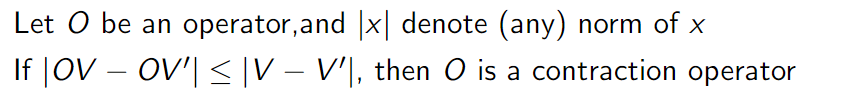
If discount factor \(\gamma<1\), or end up in a terminal state with probability 1
Bellman backup is a contraction if discount factor, \(\gamma<1\)

Value Iteration vs Policy Iteration

'Deep Learning' 카테고리의 다른 글
| [CS234] Reinforcement Learning: Lecture 4 (0) | 2024.07.17 |
|---|---|
| [CS234] Reinforcement Learning: Lecture 3 (0) | 2024.07.16 |
| [CS234] Reinforcement Learning: Lecture 1 (0) | 2024.07.10 |
| [coursera] Sequence Models: Week 4 (0) | 2024.07.09 |



