
ROKO
[CS234] Reinforcement Learning: Lecture 3 본문
Lecture 1,2 에서는 world, environment가 어떻게 구성되고 돌아가는지 알고 있는 가정에서 살펴보았다.
흔히 model-based method라고 불리는데 이번 lecture에서는 world를 모르는 model-free에 대해서 알아본다.
Policy evaluation
Estimating the expected return of a particular policy if don't have access to true MDP models
Monte Carlo policy evaluation
- Policy evaluation when don't have a model of how the world work
Monte Carlo (MC) Policy Evaluation


만약 policy로부터 sampling한 모든 trajectory가 finite하다면 평균 return값을 사용한다는 것이다. policy로 부터 생성된 episode는 terminal state에 도달했을때 하나의 trajectory가 생성되는 것이므로 terminal state에 도달하지 못하면 무한한 길이를 가지게 된다. MC는 terminal state에 도착한 episode를 가지고 update하므로 infinte한 길이는 다룰 수 없다.
MC의 특징으로는 아래와 같다.

Markov 상태 추정을 하지 않는다는 뜻은 이전 state뿐만 아니라 episode 전체를 통해 update하기 때문이다.
MC를 통해 policy evaluation을 할때 대표적인 문제점이 있다. episode 속에서 어떤 state s를 2번 방문하게 된다면 첫번째 return값을 써야할까 두번째 return값을 써야할까? 이를 first-visit or every-visit이라고도 부른다.
First-Visit / Every-Visit Monte Carlo (MC) On Policy Evaluation


차이점은 counter에 있다. first-visit의 경우 first-visit의 값만 사용하면 그만이고 every-visit인 경우 같은 노드에 방문할때마다 counter+1해주어 average return 값을 사용한다.
average return 값을 구하는 과정에서 counter값을 사용하는데 매 counter가 +1 될때마다 평균을 구하는건 꽤 비효율적이다. 이를 단순화하기 위해서 incremental average sum을 사용한다.
incremental average sum 이랑 그냥 average랑 같아 보이는데 뭐가 비효율이라는거지..?
→ 컴퓨터의 기본 사칙연산을 기준으로 생각해보면 차이가 있다는 것을 알 수 있다.
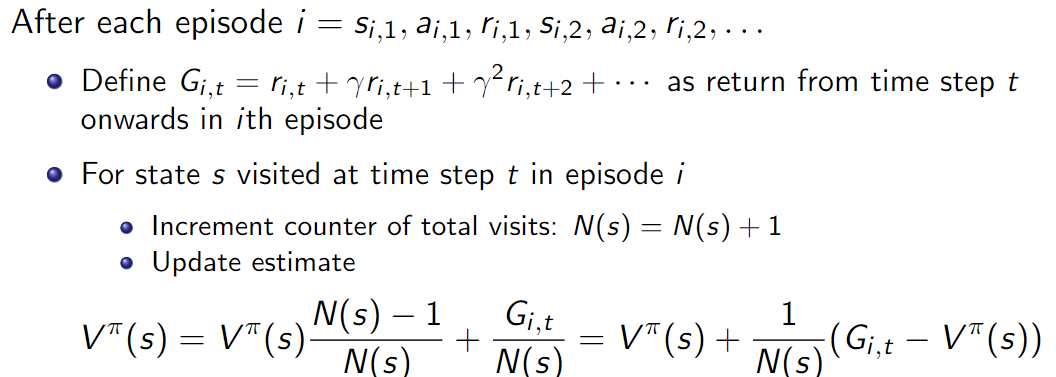
중복 횟수가 충분히 큰 수가 된다면 이후의 return값은 0에 가까운 영향을 주게 된다. 하지만 실제로 policy가 update하는 과정에서 후반부의 return값이 중요한 경우가 있을 수 있기 때문에 충분히 작은 고정 상수 \(\alpha\)를 사용해 이 문제를 완화한다.

Evaluation of the Quality of a Policy Estimation Approach
- Consistency
- Computational complexity
- Memory requirements
- Statistical efficiency
- Empirical accuracy
Policy estimation 방법의 quality는 Bias, Variance, MSE를 이용해 평가한다.

생각해보자, 모델이 consistency하다면 해당 모델은 unbiased하다. 역은 어떨까?

정답은 Not sure다. target population과 estimator distribution이 일치한다면 그렇지만 아닌 경우 보장 할 수 없다.
관련 reference를 읽어보면 도움이 된다.
What is the difference between a consistent estimator and an unbiased estimator?
What is the difference between a consistent estimator and an unbiased estimator? The precise technical definitions of these terms are fairly complicated, and it's difficult to get an intuitive fee...
stats.stackexchange.com
https://personal.utdallas.edu/~scniu/OPRE-6301/documents/Estimation.pdf [8 page ~ consistency sector]
Properties of Monte Carlo On Policy Evaluators

Bias, consistent estimator 를 가지고 각 MC 방법을 평가한 결과이다.

CS234 3강에서 가장 이해하기 어려웠던 부분이다. 말하고자하는 바는 이해했고 이 조건으로 수렴하는것도 이해하지만 이 조건이여야만 하는지 다른건 안되는지에 대한 생각이 들었다. anotated 된 자료에도 별다른 얘기가 없고 다른 정리 블로그나 수업자료에도 명시되어 있지 않았다. 그러던 중 구글링을 통해 명확한 이유를 알 수 있었다. 해당 자료를 참고하여 읽어보면 좋을것 같다.
https://stackoverflow.com/questions/59709726/criteria-for-convergence-in-q-learning
Criteria for convergence in Q-learning
I am experimenting with the Q-learning algorithm. I have read from different sources and understood the algorithm, however, there seem to be no clear convergence criteria that is mathematically bac...
stackoverflow.com
https://link.springer.com/article/10.1007/BF00992698[pdf page 표기 58 ~ Theorem]
Monte Carlo (MC) Policy Evaluation Key Limitations

Note: Sometimes is preferred over dynamic programming for policy evaluation even if know the true dynamics model and reward.
모델을 알고 있음에도 MC가 선호되는 경우는 모델이 너무 커서 computational cost가 큰 경우라고 생각한다. MC는 sampling한 episode들로 학습하면 되므로 비교적 효율적일 수 있다.
Temporal Difference (TD)
- Combination of Monte Carlo & dynamic programming methods
- Model-free
- Can be used in episodic or infinite-horizon non-episodic settings
- Immediately updates estimate of V after each (s,a,r,s') tuple

Temporal difference의 기본 알고리즘이다. 수식에는 MDP를 알고 있다는 가정에서 수식이 쓰여있다. TD는 General Policy Iteration의 one-step transition, 즉 DP의 bootstrapping과 MC의 sampling을 합친 방식이다.
Temporal Difference [TD(0)] Learning


TD 문제

정답은 2,3,4 이다. 1번은 수식을 보면 알겠지만 초기 policy에서 update되지 않는다. \(\alpha=1\)이라는 의미는 직전의 action만 고려한다는 뜻이다. 따라서 2번은 참이고 3번도 직전의 행동만 고려하므로 여러 가능한 모든 state 를 방문할 때마다 해당 state에 최적화되어 진동하게 된다. 4번은 직전 action만 고려하는 환경에서는 올바른 추정이므로 참이다.
Certainty Equivalence \(V^{\pi}\) MLE MDP Model Estimates
- Model-based option for policy evaluation without true models

True model에서 얻어진 MLE (maximum likelihood) 또한 True이다. transition probability를 모르는 상황에서 경험한 episode를 바탕으로 MLE를 추정할 수 있고 이는 True model에 근사한 확률값을 가질 수 있다. 즉 경험으로부터 임의의 MLE를 통해 MDP를 추정하고 model-based method를 사용하는 것이다.
- Analytic matrix solution has \(O(|S|^3)\) and iterative methods has \(O(|s|^2|A|\) as updating cost
- data efficient but computationally expensive
- Consistent
- Can easily be used for off-policy evaluation
Batch Policy Evaluation
- Batch (Offline) solution for finite dataset
- Given a set of K episodes
- Repeatedly sample an episode from K
- Apply MC or TD(0) to the sampled episode
AB Example: (Ex. 6.4, Sutton & Barto, 2018)

8번의 episode로 부터 얻은 결과이다. A를 거친 episode는 1번밖에 없는데 경험상으로 최악의 선택임을 알았다. 그러나 우리가 바라봤을땐 그저 우연히 A인 경우에 실패해서 A의 선택 자체가 안좋은 선택으로 낙인이 찍혀버린것을 알 수 있다.

AB example에 대한 MC와 TD의 결과를 비교해보자. MC 의 경우는 최종적으로 얻은 return을 업데이트하기 때문에 V(A)=0이라는 결과가 나왔지만 TD는 temporal하게 update하기 때문에 V(A)=3/4라는 추정을 얻었다. 이는 DP with certainty equivalence와 동일하다고도 볼 수 있고 markov property가 적용되는 모델이기 때문에 MC보다 더 좋은 결과를 보인다.
MC vs TD


- 1번 false, 대입해보면 policy의 update 안되기 때문이다
- 2번 true, 정의에 의해 참이다
- 3번 true, non-stationary domain의 경우 이전 step의 선택과 무관할 수 있기 때문이다
'Deep Learning' 카테고리의 다른 글
| [CS234] Reinforcement Learning: Lecture 5 (0) | 2024.07.29 |
|---|---|
| [CS234] Reinforcement Learning: Lecture 4 (0) | 2024.07.17 |
| [CS234] Reinforcement Learning: Lecture 2 (0) | 2024.07.11 |
| [CS234] Reinforcement Learning: Lecture 1 (0) | 2024.07.10 |



