
ROKO
[coursera] Neural Networks and Deep Learning: Week 1 본문
[coursera] Neural Networks and Deep Learning: Week 1
RO_KO 2024. 6. 28. 21:33
신경망 (neural networks)은 input으로부터 output을 예측하도록 하도록 하는 알고리즘이다. 이때 hidden units은 input 값에 의존적이며 구체적인 특징 값을 의미하지 않고 그저 output을 잘 예측하기 위한 임의의 값으로 학습된다.
현재 경제적 가치를 이끌어내는 딥러닝은 대부분 지도학습 (supervised learning)을 이용한 모델들이다. 지도 학습이란 input(x)에 대해 대응되는 output(y)가 존재하는것을 의미하고 모델은 input x에서 output y로 매핑하기 위한 함수를 학습한느것이 목적이 된다. 쉽게 말하면 데이터에 대한 정답이 주어진 환경을 학습하는 것을 말한다.
| Input (x) | Output (y) | Application |
| Home features (부동산 요인) | Price | Real Estate (부동산) |
| Ad, user info (광고, 사용자 정보) | Click on ad (클릭 횟수) | Online Advertising (온라인 광고) |
| Image | Object (객체 개수) | Photo tagging (사진 태깅) |
| Audio | Text transcript (대본) | Speech recognition (언어 인식) |
| English | Chinese | Machine translation (번역) |
| Image, Radar info (레이더 정보) | Position of other cars | Autonomous driving (자율주행) |
각 input domain마다 더 효율적인 신경망 구조가 존재한다. 예를 들어 Image의 경우 CNN, Audio의 경우 RNN 기반 구조가 좋다. 용어로 설명하자면 데이터는 크게 정형 데이터와 비정형 데이터로 구분된다.
정형 데이터
데이터의 형태가 구조화 되어있는것을 말한다. (table, database)
| Size | #bedrooms | ... | Price |
| 2104 | 3 | 400 | |
| 1600 | 3 | 300 |
비정형 데이터
데이터의 형태가 정의된 구조가 없이 정형화되지 않은 데이터를 말한다. 딥러닝은 비정형 데이터를 다루는데 특히 효과적이다.
모델과 데이터 스케일의 관계
라벨링이 되어있는 데이터셋의 크기와 모델의 종류,크기에 따른 성능 변화를 나타낸 그래프이다.● 색 그래프는 전통적인 머신러닝 알고리즘을 의미한다. 전통적인 머신러닝은 데이터가 증가하더라도 어느 순간부터 성능이 수렴하는 현상을 보이는 반면 딥러닝 알고리즘은 데이터의 증가와 그에 맞게 모델의 크기가 커질수록 ● → ● → ● 성능이 계속 증가하는것을 볼 수 있다.
하지만 데이터가 적은 small training sets에 영역에서는 알고리즘간의 절대적인 차이가 잘 드러나지 않고 사용자의 feature engineering 능력에 더 크게 성능이 반응한다.
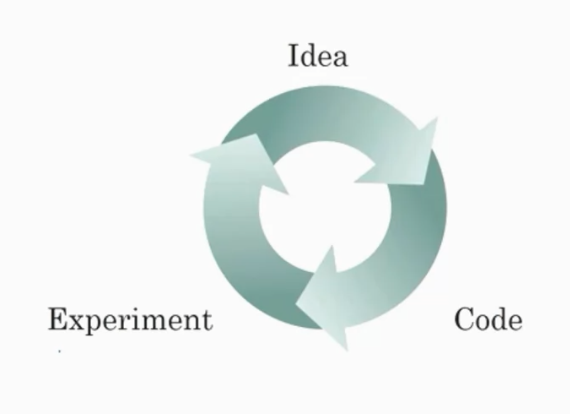
딥러닝은 3가지에 영향을 크게 받는다.
- Data
- Computation
- Algorithms
각 3가지 모두 프로젝트 과정 시간에 영향을 주는 요인이다. 좋은 GPU 하드웨어와 효율적인 데이터 전처리 코드 그리고 최적화된 알고리즘 코드를 구현 할 수 있다면 위 그림과 같은 연구의 프로세스를 남들보다 빠르게 진행할 수 있고 더 좋은 insight를 얻을 수 있을 것이다. (개인적으로 깊이 동의하는 내용이라고 생각한다.)
# 코세라 1주차 마지막에 제프리 힌턴과의 인터뷰가 있는데 간접적으로나마 그의 연구 가치관을 엿볼수 있어 너무 좋았다.
'Artificial Intelligence > Deep Learning' 카테고리의 다른 글
| [coursera] Neural Networks and Deep Learning: Week 3 (0) | 2024.06.29 |
|---|---|
| [coursera] Neural Networks and Deep Learning: Week 2-2 (0) | 2024.06.29 |
| [coursera] Neural Networks and Deep Learning: Week 2-1 (0) | 2024.06.29 |
| AE (Autoencoder) (0) | 2023.03.07 |



